
تمرکززدایی محاسبات در حال تغییر روشهای جمع آوری، ذخیره، پردازش و انتقال داده ها ؛ توسط کسب و کارها است. معماریهای نوظهور به جای اینکه همه چیز را در یک مرکز داده مرکزی قرار دهند، منابع محاسباتی و ذخیرهسازی را خارج از مرکز داده و به نقاطی که دادهها در آن جمعآوری میشوند ، نزدیکتر میکنند. این ایده های اساسی ( معماریهای نوظهور ) را Fog computing و edge computing می نامند. اما اصطلاحات ناشی از این تغییر الگو ( paradigm ) ، گاهی اوقات ممکن است گیج کننده باشد. بیایید مفاهیم را به تفصیل بیان کنیم و تفاوت های آنها را با دقت بیشتری بررسی کنیم.
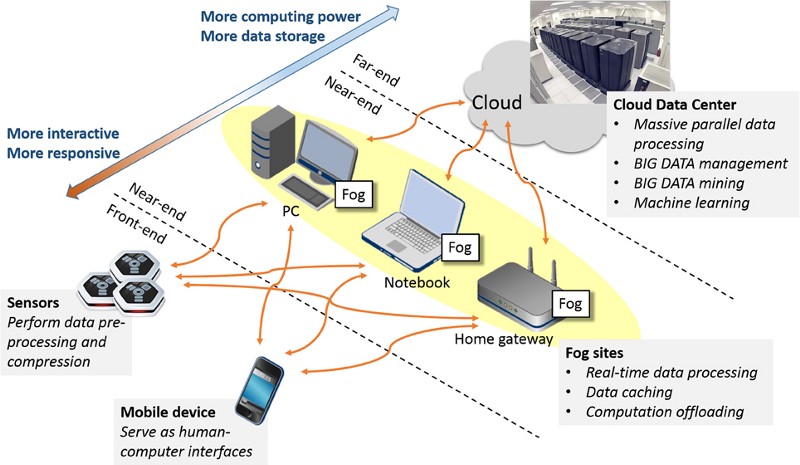
Fog computing و edge computing مفهومی تقریباً یکسان دارند: برای دور کردن محاسبات و ذخیره سازی از محدوده یک مرکز داده متمرکز و توزیع آن منابع در یک یا چند مکان اضافی در سراسر محیط شبکه ای که گسترده تر است. در حالت ایده آل، منابع غیرمتمرکز به نقطه ای که کار در آن انجام می شود نزدیک تر خواهد بود. این کار می تواند جمع آوری داده یا پردازش درخواست کاربر باشد.
چرا این موضوع مهم است؟ همه چیز در مورد شبکه هاست. یک شبکه فقط میتواند حجم محدودی از دادهها را در طول زمان (پهنای باند) مدیریت کند و برای جابجایی دادهها در فواصل جغرافیایی بزرگ ( latency ) زمان محدودی طول میکشد. از آنجایی که کسبوکارها به طور فزایندهای به حجم بیشتری از دادهها برای ارائه خدمات به مخاطبان جهانی بیشتر تکیه میکنند، شبکهها برای مدیریت بار تلاش میکنند و کاربران باید مدت بیشتری منتظر پاسخ باشند. روش سنتی که کسب و کارها با محاسبات مدیریت می کنند به آرامی متوقف می شود. معماران سیستم و شبکه مدت هاست به دنبال راهی برای کاهش این بار از دوش شبکه بوده اند.
در یک رویکرد محاسباتی سنتی، دادههایی که در یک مکان دور جمعآوری میشوند، ( معمولاً برای اهداف تحلیلی ) سپس به یک مرکز داده مرکزی منتقل میشوند ؛که در آن دادهها میتوانند ذخیره و پردازش شوند . اما هیچ قانونی وجود ندارد که ذخیره سازی و محاسبات را متمرکز کند. این فقط رویکردی است که طی دهه ها تکامل یافته است.
edge computing و Fog computing به دنبال قرار دادن منابع ذخیره سازی و محاسباتی بسیار نزدیکتر یا حتی در مکانی هستند که داده ها در آن تولید می شوند. این حالت به طور موثر نیاز به جابجایی حجم بالایی از داده های خام را در فواصل بزرگ از طریق شبکه کاهش می دهد یا حذف می کند. سخت افزار و نرم افزار مورد استفاده برای انجام وظایف محاسباتی، اساساً یکسان هستند. برای مثال، اگر تاسیسات یا مرکزی داده ای ؛ دادهها را تولید کند و آن دادهها مستقیماً در edge سایت همان مرکز داده ای پردازش شود، نیازی به اتکا به اینترنت نیست.

به عنوان یک مثال دقیق تر، یک کارخانه کنترل از راه دور با ماشین های بی شمار مجهز به دستگاه های IoT بی شماری را در نظر بگیرید که برای نظارت و کنترل مجموعه ای از شرایط فیزیکی و پارامترهای عملیاتی در کل نصب کارخانه استفاده می شود. در یک محیط سنتی، تمام دادههای دستگاه IoT باید از طریق یک شبکه WAN – مانند اینترنت – به مرکز تجاری منتقل شوند، جایی که دادهها میتوانند پردازش و تجزیه و تحلیل شوند. با قرار دادن منابع ذخیره سازی و محاسباتی در آن کارخانه یا نزدیک آن، داده ها را می توان بصورت کارآمدتر پردازش و تجزیه و تحلیل کرد، به گونه ای که معمولاً بدون ازدحام و اختلالات اینترنت، و فقط نتایج تحلیلی باید در دسترس مرکز داده اصلی باشد.
اینجاست که مفهوم edge computing و Fog computing شروع به واگرایی می کند. Fog معنای وسیع تری به خود می گیرد و می تواند منابع ذخیره سازی و محاسباتی درگیر در هر تعداد مکان و اتصالات را در بر بگیرد. برای مثال، اگر یک کارخانه، دادهها را برای پردازش به منطقه محلی یا حتی یک ارائهدهنده ابری به یک مرکز داده همزمان نزدیک بفرستد، میتوان آن را بهعنوان Distributed computing و Fog نامید تا ایده دقیقتر edge فیزیکی.
- چهار مزیت کلی برای آنها وجود دارد:
1- کاهش تأخیر و بهبود زمان پاسخ : زمان مورد نیاز برای جابجایی حجم زیادی از داده ها به طور چشمگیری کاهش می یابد یا حتی حذف می شود و زمان بهتری را برای ارزش گذاری برای مجموعه داده های بزرگ فراهم می کند. اگر یک کسب و کار باید تصمیمات یا پاسخ های حیاتی در مورد آن داده ها اتخاذ کند، مانند شرایط یک مرکز صنعتی بزرگ؛ تأخیر کاهش یافته زمان پاسخ را بهبود می بخشد و از اختلالات شبکه جلوگیری می کند.
2- بهبود امنیت و انطباق پذیری : انتقال داده های خام در یک شبکه عمومی می تواند آن داده ها را در معرض خطر قرار دهد و به طور بالقوه وضعیت انطباق سازمان را به خطر بیاندازد. حفظ داده ها در محل یا کاهش زیاد مسافتی که داده ها باید طی کنند، می تواند سطح حمله احتمالی برای جاسوسی یا سرقت داده ها را کوچک کند. علاوه بر این، به حداقل رساندن مقدار داده خام در معرض دسترسی یک شبکه عمومی می تواند به طور بالقوه انطباق را بهبود بخشد، تا زمانی که داده ها به اندازه کافی در edge یا fog nodes ؛ ایمن باشند.
3- کاهش هزینه ها و کاهش نیاز پهنای باند : نیاز به پهنای باند برای مجموعه داده های بزرگ ، سریعتر از ظرفیت عمومی شبکه در حال افزایش است. نیاز به پهنای باند بالا می تواند هزینه قابل توجهی را بر تجارت تحمیل کند. اجتناب از نیاز به پهنای باند بالا می تواند در هزینه های اینترنت صرفه جویی کند.
4- استقلال بیشتر و کاهش اختلال : محدود کردن الزامات WAN همچنین می تواند از اختلالات احتمالی ناشی از ازدحام و قطعی شبکه WAN جلوگیری کند. اگر یک مرکز edge داده ها را در محل ذخیره و تجزیه و تحلیل کند، حتی در صورت قطع اینترنت می تواند به کار خود ادامه دهد. برای تأسیسات fog که ممکن است از سایتهای بیرونی برای ذخیرهسازی و محاسبات استفاده کنند، فاصلههای WAN کوتاهتر میتواند تأثیر اختلالات WAN را کاهش دهد.
- با این حال، با وجود مزایا، چندین معایب کلی وجود دارد که کاربران Fog و edge می توانند با آن مواجه شوند:
* افزایش پیچیدگی : یکی از مزایای کلیدی محاسبات مرکز داده سنتی این است که منابع و خدمات اصلی همه در یک مکان هستند. محاسبات مه و لبه این الگوی سنتی را خنثی میکند و منابع و خدمات را در مکانهای دوردست و نزدیک به نقطهای که دادهها تولید میشوند، توزیع میکند. این معماری محاسباتی توزیع شده ، منجر به محیطی می شود که طراحی، پیاده سازی و نگهداری آن پیچیده تر است.
* نگرانی های امنیتی : امنیت بصورت بومی و ذاتی در فن آوری های Fog و edge ، وجود ندارد. اگرچه امنیت را می توان با Fog computing و edge computing افزایش داد، اما امنیت بهتر به دور از اطمینان در این محاسبات است. معماریهای Distributed computing باید به تمام جنبههای امنیتی از حفاظت از دادهها و رمزگذاری گرفته تا دسترسی و احراز هویت و امنیت فیزیکی، بپردازند.
* مدیریت غیر متمرکز : شما نمی توانید آنچه را که نمی بینید، مدیریت کنید. مدیریت دستگاه های کنترل از راه دور می تواند برای ابزارهای مدیریتی مشکلاتی ایجاد کند و مهم است که هر ابزار مدیریتی از حضور زیرساخت های توزیع شده پشتیبانی کند. این وضعیت ممکن است در نهایت شامل ابزارهای متعددی مانند ابزارهای مدیریت ابر، ابزارهای پیکربندی و مدیریت اینترنت اشیا، و ابزارهای مدیریت مرکز داده مرسوم مناسب برای زیرساخت های راه دور یا توزیع شده باشد. صرفنظر از مجموعه ابزار واقعی، فرآیند تهیه و مدیریت نسبت به جریانهای کاری متمرکز سنتی؛ بیشتر درگیر و زمانبر خواهد بود.
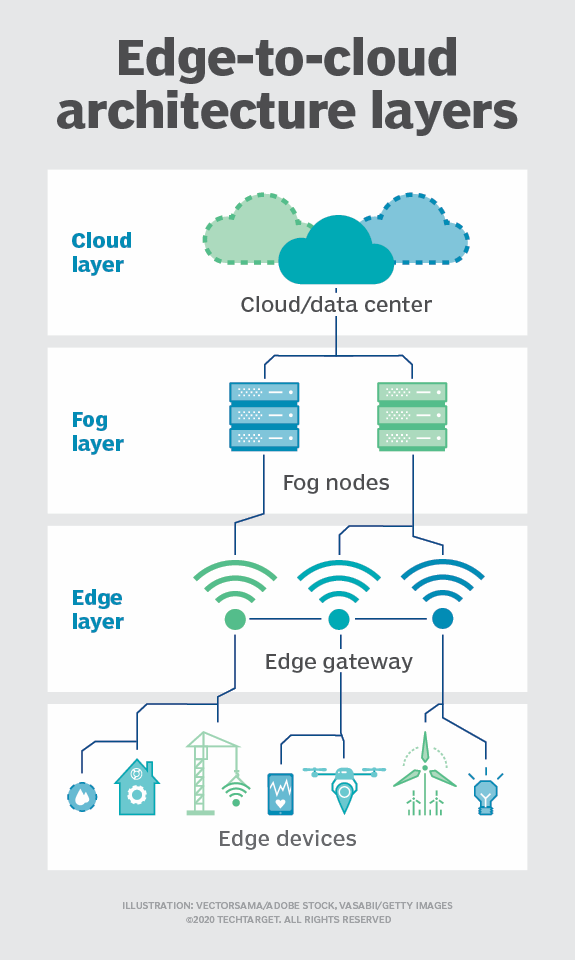
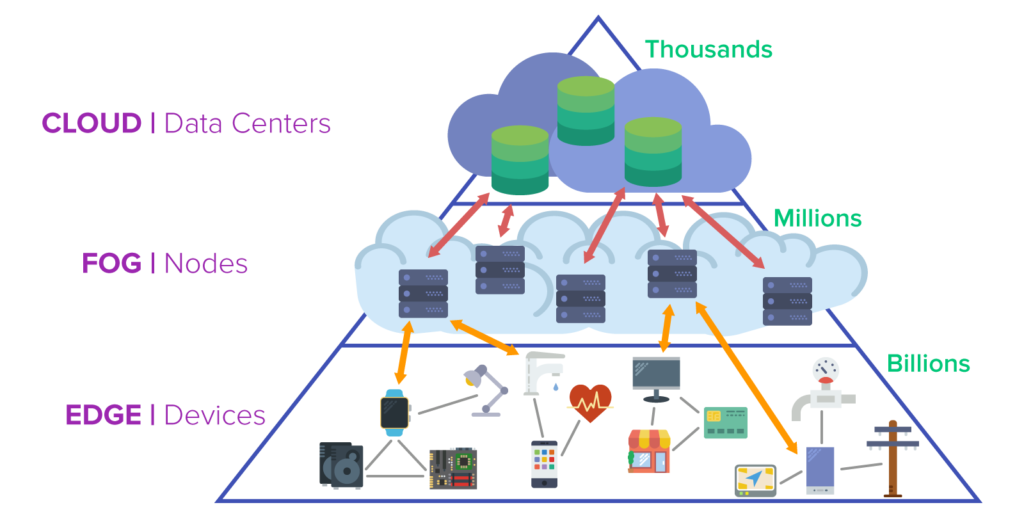
تفاوت بین این دو مفهوم مرتبط با اینترنت اشیا تا حد زیادی بستگی به این دارد که از چه کسی بپرسید. در اینجا، ما سه روشی که ممکن است این اصطلاحات نوظهور را بشنوید و تفاوت این اصطلاحات را ؛ بررسی می کنیم.
1- یک اصطلاح : بسیاری از متخصصان فناوری اطلاعات از اصطلاحات محاسبات Fog و edge به طور گسترده و به جای یکدیگر برای اشاره به توزیع منابع محاسباتی و ذخیره سازی در اطراف یا نزدیک به شبکه استفاده می کنند.
یک مدل Decentralized edge or fog ، دادهها را در یا نزدیک به نقطه مبدا پردازش میکند نه در یک مرکز داده دوردست یا ابر. این حالت منجر به تأخیر کمتر برای دستگاه های تلفن همراه و اینترنت اشیا و به طور کلی تراکم شبکه کمتر می شود.
2- اصطلاحات مجزا، اما مرتبط : سایر کاربران از تعاریف دقیق تری استفاده می کنند که بین edge computing و Fog computing تمایز قائل می شوند.
کنسرسیوم OpenFog ، استدلال میکند که Fog به معماری گسترده فناوری اطلاعات اشاره دارد که شبکه پیچیدهای از ارتباطات متقابل پویا را ایجاد میکند.
این اتصالات می تواند از دستگاه های edge تا تکنولوژی ابری ، منابع محاسباتی و ذخیره سازی محلی مشترک مانند دروازه های اینترنت اشیا؛ و سایر دستگاه های edge ؛ گسترش یابد.
پیرو OpenFog گفته میشود Fog computing ، که به آن fog networking و fogging نیز می گویند، گسترش تکنولوژی ابری تا edge را استاندارد می کند و تمام فضا و فعالیت بین این دو را در بر می گیرد.
edge computing ، در این مورد، از نظر دامنه محدودتر است، زیرا به نمونههای جداگانه و از پیش تعریفشده پردازش محاسباتی اشاره دارد که در نقاط پایانی شبکه یا نزدیک به آن اتفاق میافتد. با این الگو ، edge computing نمی تواند به تنهایی اتصالات شبکه ای مستقیم بین دو نقطه پایانی یا بین یک نقطه پایانی و یک دروازه اینترنت اشیا ایجاد کند. برای آن منظور ، به Fog نیاز دارد.
از نظر OpenFog گفته میشود که ، Fog computing همیشه از edge computing استفاده می کند. با این حال، edge computing ممکن است از Fog computing استفاده کند یا نه. همچنین، طبق تعریف، Fog شامل تکنولوژی ابری می شود، در حالی که edge اینطور نیست.
3- شرایط به مکان بستگی دارد. با این حال، دیگر متخصصان فناوری اطلاعات می گویند که استفاده از Fog computing در مقابل edge computing به طور خاص به محل Distributed computing و منابع ذخیره سازی بستگی دارد. اگر قابلیت های پردازش مستقیماً در یک endpoint متصل تعبیه شده باشد، آن را edge computing می نامند. اما، اگر اطلاعات در یک گره شبکه جداگانه مستقر بین یک endpoint و تکنولوژی ابری ، مانند یک گره محلی یا دروازه اینترنت اشیا قرار داشته باشد، آنگاه Fog نامیده میشود.
منبع :
گرد آوری ، ترجمه و تنظیم : ” بهشاد ابرقوئیان “
#تکباکس_آی_آر #تکباکس_ایران #ذخیره_ساز #سرور #وای_فای #اینترنت_اشیا #رایانش_مه #رایانش_ابری #گره
#techboxir #techboxiran #server #storage #network #wi_fi #IoT #fogcomputing #cloudcomputing #edgecomputing #openfog #5G #node #endpoint